Below shows my data science projects:
Project 1: Metacritic Bias Detection (NLP)
- The most controversial game of 2020, The Last of Us: Part II sparked disparity amongst critics and users around the world and this is evident on Metacritic, the review aggregator website. The game scored 94 out of 100 overall from critics – one of the most highly acclaimed games ever. However, the overall user score was 5.6 out of 10 denoting a low-average review score.
- Two deep neural networks were created to detect the level of bias in reviews on the site Metacritic for the top 25 and worst 25 video games of all time.
- The first model was trained using an Amazon dataset reviewing fine foods on the Kaggle website.
- The second model was trained using data scraped from Metacritic using 22 games.
- An in-depth analysis was carried out using both models on the reviews of three games on Metacritic. One of them being The Last of Us Part II.
- Below shows the accuracy of the superior Amazon model (74% accuracy):
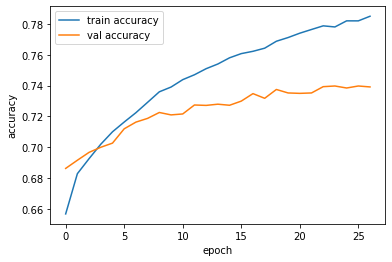
- Against the inferior Metacritic model (68% accuracy):
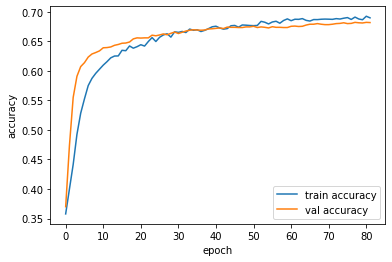
- Follow the link for more detail.
Project 2: Classification of Artificial Data using K Nearest Neighbors (KNN)
- This project predicts the class of 10 different conntinuous features using a KNN model.
- The variables are normalized using sklearn’s StandardScaler
- The classifier is initially run with K = 1 to show the lower precision, recall and f1-score values
- An elbow plot for error rate vs K value is created to find the value of K with the lowest error:
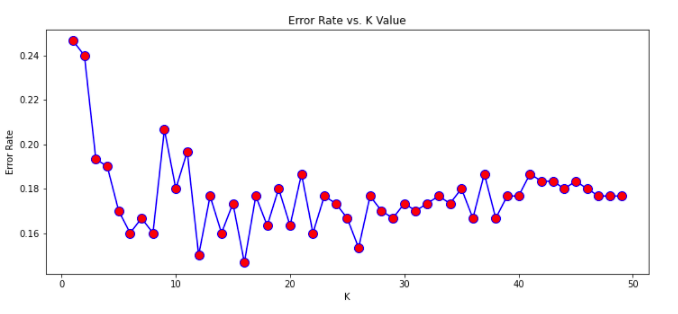
- K = 31 is used and presents a far better f1-score than the K = 1 model.
- Follow the link for more detail.
Project 3: Firm Disciplinary Action (Logistic Regression)
- This project looks at whether a law firm needs disciplinary action from a company based off 11 variables. The data is from the recrutiment process for the solicitors Regulation Authority (SRA).
- Outliers were removed from the dataset and multicollinearity was examined using a heatmap:
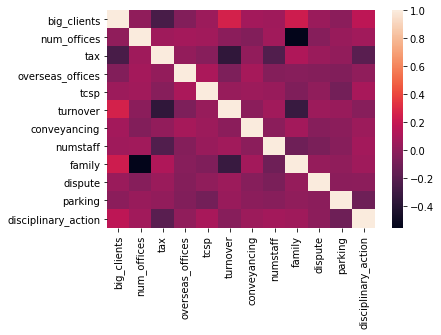
- For logistic regression it is important to remove multicollinearity for the best results.
- Turnover and Family variables were not taken into account in the model because they create multicolinearity and they are not related to what we are trying to predict (disciplinary action).
- Overall the model was 75% accurate with its predictions.
- Follow the link for more detail.
Project 4: What needs work the App or the Website? (Linear Regression)
- A company is trying to decide whether to focus their efforts on their mobile app experience or their website.
- A linear regression was used on the DataFrame given to predict the yearly amount spent by the company.
- This led to a MAE and RMSE of 7.2 and 8.9 respectively, meaning three things:
- There is some variation in the magnitude of errors.
- Very large errors are unlikely to have occured.
- The average distance between the forecast and observed amount was 7.2 dollars.
- The coefficients of the model are shown below
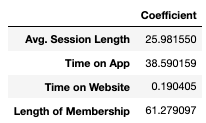
- It was found that the company should focus on their website more.
- Follow the link for more detail.
Project 5: Diabetic or not? (Exploratory Data Analysis)
- A dataset based around whether a person was diabetic or not was taken from Kaggle (https://www.kaggle.com/). I then carried out an exploratory data analysis to see which variables were related, and which would be suitable to predict whether a person was diabetic.
- As the majority of variables were binary/cateogrical they could be plotted using countplots:
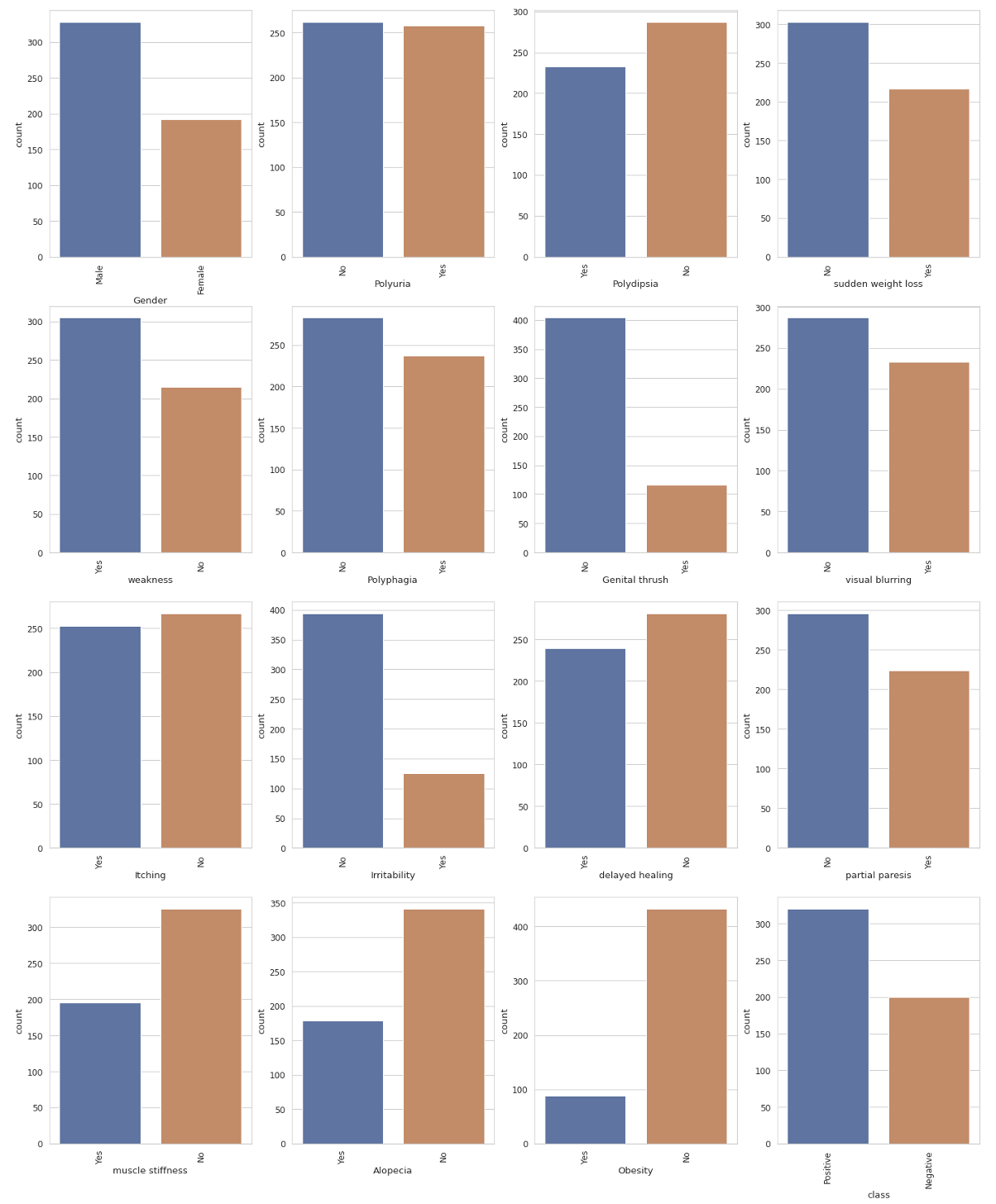
- Data was then imputed with 1’s and 0’s in order to make a heatmap to compare all variables and examine multicollinearity.
- After examining the dataset it was found that Gender, Polyuria, Polydipsia and Alopecia are all related to whether a person is diabetic and would be the best predictors if a model were to be created.
- Follow the link for more detail.